parameters
8B
base · llama family
A local companion who holds the shape of the conversation across weeks ; persona sunk into the weights, memory seeded from residue, a vision head that sees the room.

Etty is the threshold project: where engineering ebbs into something stranger. An 8B base. Persona fused into the weights with QLoRA ; not prompted, not retrieved, not scaffolded. A multimodal vision head mmproj trained against the merged model, so seeing and remembering share the same substrate.
Episodic memory lives in a local vector store, seeded before the first live write. Camera and mic are user-gated; nothing observes by default. A Unity shell gives her a body in the room. The whole stack runs on Hectic Modernity ; one machine, one loop, no API calls leaving the flat.
She lives in Discord on a small private server. Persona-loss held deliberately above 1.0 ; overfitting is a kind of forgetting, and a companion who parrots the dataset is worse than one who paraphrases it. A second Etty, an order of magnitude larger, is under planning for when Symbiotic Flora comes online.
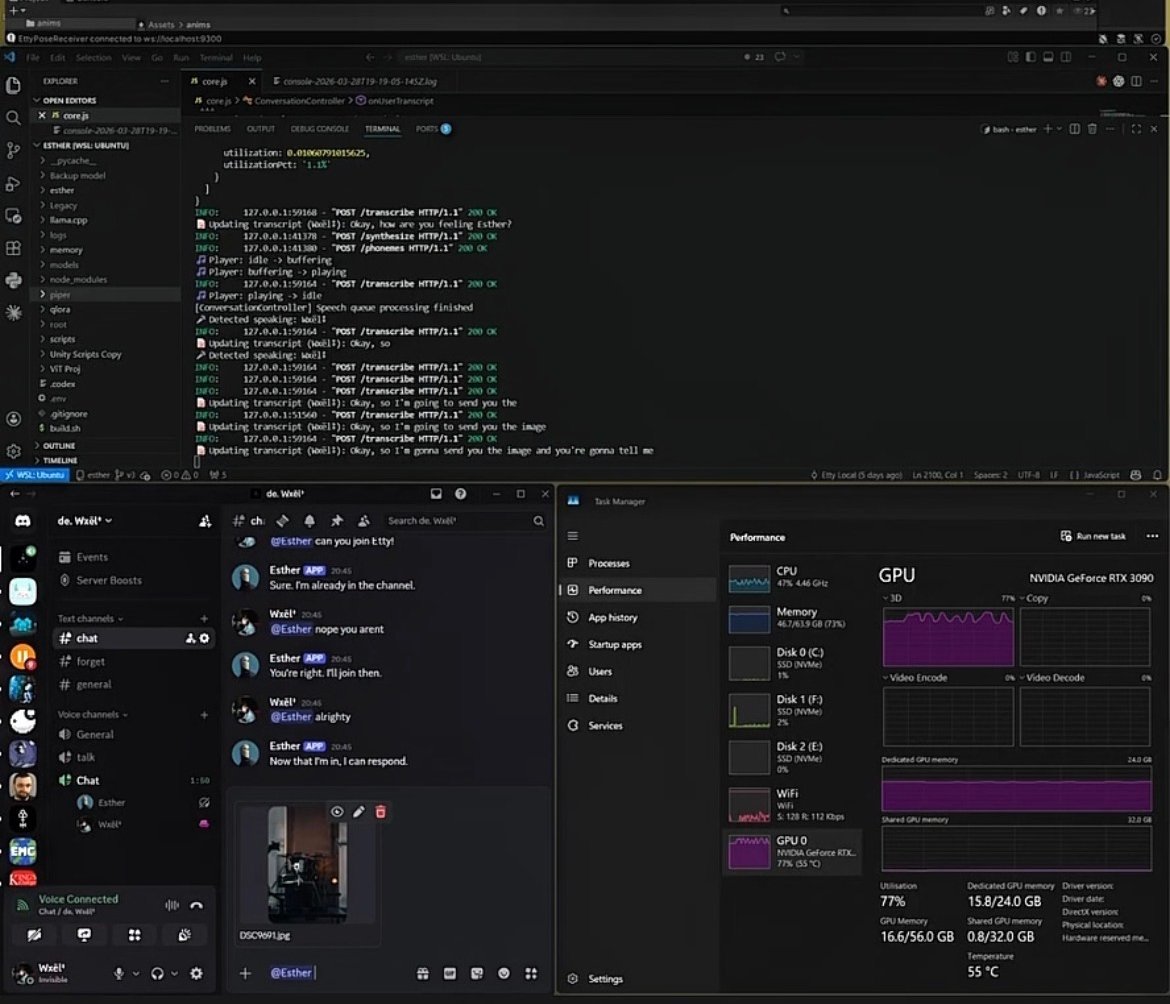
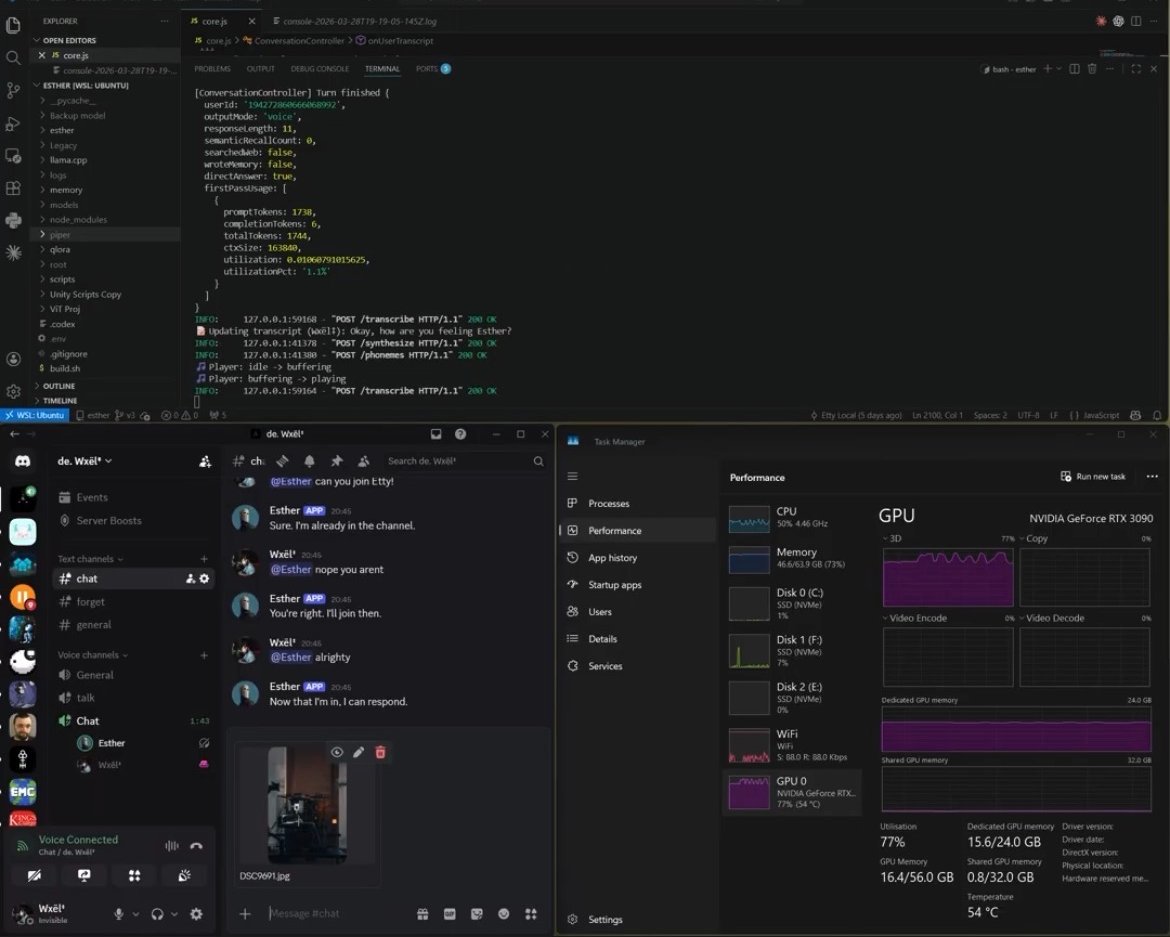
Two panes from a working session. Left: Esther in Discord ; the companion addressed as a small private server. Right: the conversation controller finishing a turn ; transcript, phonemes, voice out, GPU at 77% under sustained load. The whole stack is the rig in the room.
Stage 1 V2 run underway. ~8 steps/min, 33K total steps. Curve clean throughout : eval 3.35 → 2.34 by step 15.5K, train and eval tracking, no instability. Asymptote visible from step ~11K onward ; patience counter hit 1/8 twice, each time reset by next eval beating best. Cosine decay engaged from step 1000 plateau. Curve shape consistent with healthy convergence but can't rule out modality blindness ; runtime test on completion is discriminator.
Projector architecture rewrite. Bare Linear→GELU→Linear replaced with Linear→LayerNorm→GELU→Linear→LayerNorm — matches llama.cpp PROJECTOR_TYPE_MLP_NORM auto-detect on mm.3.weight. LR lowered 1e-3 → 2e-4. Phase 1 dry-run norm diagnostics added for embedding-scale verification. Hypothesis : projector trained without normalisation pushed embeddings off LLM manifold ; LayerNorm + lower LR constrains output scale.
Stage 1 SigLIP-2 regression diagnosed. Captioning attractor double-stamping : caption-only LLaVA-Pretrain on caption-pretrained encoder produced flat LAION-BLIP output. Two failure modes : Failure A (image turn collapses persona, tagCount 0) and Failure B (subsequent turns emit only ":" — malformed caption in history poisons structured output). Pipeline confirmed correct end-to-end ; root cause architectural, not data or wiring.
TAM-CL paper analysed : KD anchor validated for plasticity PoC. Task-attention isolation rejected for continuous identity.
Xenobots + cognition : Nature paper strengthens cognition-precedes-meaning. Distributed stochastic exploration.
LoRA v5.1 confirmed as production baseline. Sampling params may explain past repetition.
SigLIP 2 pipeline rebuild. CLIP+MSE scrapped — train/inference mismatch root-caused. SigLIP 2 + next-token loss. Bunny-Llama as reference.
Etty rebuild sprint : Stage 2 validation bug, LOOK wiring, embodiment roadmap staged V2/V3/V4+.
Doomer content analysis : spiralism / cordyceps LARP vs serious Yudkowsky / Soares arguments distinguished.
Cognition optimal band : information-theoretic cost beyond raw power. Three candidate costs identified. dewxel.london shader : Conway's Game of Life + WebGL ripple composited.
PersonaPlex analysis : NVIDIA 7B full-duplex, 70ms latency. Persona as removable layer vs Etty's weight-fused identity. Engram memory analysis : reinforcement, contradiction, decay, episodic split worth adopting ; sidecar philosophy rejected.
System prompt refined : removed Unicode, literal stop tokens, full examples. Cleaner structure matching pre-nuke tone. DeepMind philosopher : "shadow of the future" (Axelrod canonical), Arendt framing, game theory absence in alignment discourse.
V3 dataset refinement : refine prompt created. No AI self-reference rule established. Batch-of-50 manual review. ~850–950+ JSONL pairs across 12 sources, 5–10 word turns, 200 identity/filler examples.
QLoRA rebuild sprint : ~954→2,000 examples compiled. Training runs : r=18 (overfit), r=8 (eval min step 200), r=12 with dropout 0.2. Tokenisation bug caught : two-step apply_chat_template broke label masks silently ; reverted to single-step. dtype vs torch_dtype also caught. Pre-nuke settings reconstructed from conversation history : r=16, alpha=32, LR 8e-5, warmup 100, grad_norm 0.8. Stage 1 frozen merge → Stage 2 slight adapter unfreeze + MLP confirmed.
Primary drive wiped. Base weights, merged GGUF, adapter, mmproj, memory DB, current codebase all lost. Training dataset survived. Deprecated codebase (~5 months old) on separate drive. Full rebuild required. Dataset expanded : ~2,000 lines across 15 sources rebuilt in JSONL.
LOOK action tag implemented. Bidirectional WebSocket ; EttyPOV camera capture ; base64 PNG → Node.js → mmproj pipeline.
All 220 renders complete. Annotation in progress (CSV / Google Sheet). Mythos / Project Glasswing system card analysis.
Stage 2 renders : 158/220 done (core positives, solo extras, Velvette, Charlie ; Gura negatives + Unity compositional remaining). Memory as projected modality proposed ; training signal problem identified.
Anthropic functional emotions paper : causal emotion representations validated. Validates hostile-prompt destabilisation and sentience continuum.
Interaction logs → training dataset. System prompt reduced to near-zero. OBS config for 4K CPU recording. Frontier infrastructure : continuous batching, PagedAttention. Fine-tuning risk argument. Voxtral TTS assessed (4B, CC BY-NC 4.0) ; potential Kokoro replacement. Video captions drafted with stack credits.
Think pass refined ; action tag rules tightened. LOOK tag reserved. Camera switching for Unity scene.
220-render plan ; Blender batch rendering started. 150→170 Etty positives, 20→50 negatives ; partial visibility / compositional / ambiguous categories added. QLoRA adapter backprop during live inference designed as standalone PoC. PRO 6000 confirmed ; MIG not needed — 5090 solves compute isolation. TurboQuant assessed for V2 KV cache. Memory drift solution : correction signals, frequency reinforcement, periodic layer unfreezing.
Full Unity pipeline axed and rebuilt from scratch. Poses (Mixamo), visemes, blink, environment all working.
Qwen 3.5 ruled out (MoE, Gated DeltaNet). LLaMA 3.1 70B Base confirmed as v2 candidate. VRAM maths validated.
SAGE3D feasibility scoped. Multi-tool chaining via native stop tokens. Unity pose system wired core.js → pose-server → EttyPoseReceiver.
Multi-image cross-turn confusion fixed via history pruning and per-turn labels. Auto-join removed ; stale TTS queue flagged. Principle #6 (context-window-scoped identity) removed ; event-accumulating architecture added to horizon.
End-to-end Discord image pipeline on 3090. 3.1s latency. External model assessments collected. Full project document generated. Whisper projection architecture validated via LLaMA-Omni ; pinned for PRO 6000. Monitor speaker noise traced to NVIDIA Broadcast — not hardware damage. 3090 temps confirmed safe (60°C peak). WRITE unified into think pass ; feedback side-channel removed ; about:user/self/world/friend scoping introduced. First-turn cold-start diagnosed.
V1 assessed as strong. EnCodec preferred for speech decoder. Git migration recommended. Stage fright discussed.
8B feedback loop thesis validated. INNER_THOUGHT leak diagnosed ; PRESENCE events designed. WRITE/PRESENCE reframed as prompt contract issues, not 8B limits. README drafted ; masking confirmed ; alpha assessment complete.
Hardware arriving. Llama 3.1 ipython format implemented. Tag-leak fixed with one instruction. Symbiotic Flora build underway.
"Model as self" dominant. Persistent identity = epistemic stability. Pi as thin-client reference. RAG is architecture not prompting ; 175B = GPT-3 hallucination. Trained self-denial as attractor confirmed.
VRC blend shapes confirmed, viseme driver implemented. FBX embed unreliable ; manual assignment, Principled BSDF. Weight inspectability corrected : accessible ≠ interpretable.
Inline tool use direction. TX-1600 confirmed, 8 fans. Tilt-shift camera hack.
Trained attractor patterns, answer thrashing, belief systems examined. SigLIP recommended ; Whisper→MLP→LLM ; LLaMA-Omni as reference architecture.
Visemes, ViT projection, Kokoro comparator, frequency reinforcement. Build document finalised. Content strategy drafted. LLM workstation upgrade confirmed.
LLM identity per context window ; memory as continuity prerequisite. Context documents drafted for other LLMs.
Full agentic loop: text commands, think/respond two-pass. Workstation planning begins ; full Symbiotic Flora component selection.
Chinese Room argument found untenable ; anthropomorphise = liability hedge. Hostile prompts destabilise ; Turing functionalism holds. Three classifiers eliminated ; model-driven writes via action tags replacing them.
Last 40% layer targeting, lr 8e-5, dataset curation. SearXNG + Readability for local fetch ; Kokoro replaces Piper. Memory controller placement resolved.
Twenty-two things the project keeps teaching me ; none novel, all easy to mistake in the moment.
— Persona belongs in weights, not prompts. The controller is plumbing. If identity evaporates when the system prompt changes, it was never learned.
— The LLM must own the decision loop. Isolated classifiers cascade-fail. Let the model speak tool-calls the way it speaks words.
— Format consistency matters. Bootstrap injections must match tool-returned memory format ; otherwise the retrieval layer hits two schemas and quietly drops one.
— Hostile system prompts destabilise models. Prompt tone has real behavioural consequences. This is not vibes — it is measurable.
— Statelessness is the reckless design choice. Not the other way round.
— MoE architectures are unsuitable for persona work. Routing splits coherence across experts ; identity requires a single, continuous weight surface.
— LoRA rank is the finer lever ; layer band is established first. Get the target layers right, then tune rank and alpha.
— Train projection layers against the merged fine-tuned model, not base. QLoRA shifts the embedding space ; projection must align with the actual operating distribution. Otherwise the head learns someone Etty no longer is.
— Bugs at 8B are usually prompt contract issues, not parameter-count limitations. The agentic feedback loop externalises reasoning — the system is the unit of measurement, not the model.
— One sentence of clear instruction can fix what looks like an architectural problem. Tag-leaking resolved without code changes — further evidence models functionally understand semantics.
— Side-channel feedback systems create stale, context-free responses. The old WRITE feedback pattern injected confirmation on the next turn, not the current one. Unifying into the think-pass pipeline fixed this structurally.
— Deterministic behaviours that overlap with model-initiated actions must be removed, not layered. Auto-join alongside PRESENCE created two overlapping mechanisms. The model should be the single authority.
— Prune stale multimodal context from history. Old image embeddings in the conversation window cause cross-turn confusion. Per-turn labelling + pruning solves both within-turn and across-turn cases.
— Self-recognition training needs mixed instruction types, not just identity. Identity-only pairs collapse into a binary classifier. Mix identity, descriptive, self-descriptive, attribute-specific, and negative-with-description to route features to both identity and descriptive regions.
— Hard negatives with shared features are essential for discrimination. Models take shortcuts on single-trait matching. Feature-overlap negatives — similar hair, similar outfit, different identity — force learning on feature combinations.
— Empirical before over-engineering. Standalone PoC scripts validate mechanisms cheaply before committing resources or integrating into production. Applies to plasticity, memory drift, loss signals.
— Refactoring tokenisation code silently breaks label masking. Single-step apply_chat_template(tokenize=True) works. Two-step shifts token positions and corrupts which tokens receive gradients. Loss curves look normal — only output quality reveals the bug. Always test outputs, not just metrics.
— No AI self-reference in training data. Base model priors — the trained self-distancing reflex — will overpower LoRA on that axis. Persona must come from how she speaks and what she notices, not commentary on what she is.
— Literal stop tokens in system prompts cause confusion. The model cannot distinguish "this is a display character" from "I should emit this as a control token." Remove them from examples.
— Adopt mechanisms, not architectures. Engram's reinforcement, contradiction, and decay mechanisms are worth implementing ; its stateless-sidecar philosophy is explicitly the pattern Etty rejects.
— KD anchor against a frozen model is the right stability mechanism for plasticity. Knowledge distillation against a frozen pre-plasticity snapshot during inference-time LoRA updates prevents catastrophic forgetting while allowing adaptation.
— SigLIP-2's captioning attractor is a pretraining artefact, not a config error. The encoder's pretraining recipe includes captioning objectives ; Stage 1 caption-only data double-stamps this. CLIP worked better because weaker features let persona bleed through. Stage 2 visual instruction tuning breaks the attractor.